Overall Framework

Real-Time Robot Control Using Diffusion Models
Affiliation withheld for double-blind review
Diffusion models excel at generating diverse and multimodal trajectories for robotic planning, yet their iterative denoising process introduces latency that is incompatible with high-frequency closed-loop control.
To address this problem, we propose Dynamic Neural Koopman Distillation, a framework that distills multistep diffusion inference into a single forward pass while retaining the multimodal expressivity of the teacher model.
Specifically, we introduce a Factorized Dynamic Koopman layer that models the denoising process through a factorized latent transition with state-dependent modal gains.
We evaluate the proposed method on standard D4RL MuJoCo locomotion benchmarks and a physical Kinova manipulator, comparing against one-step baselines.
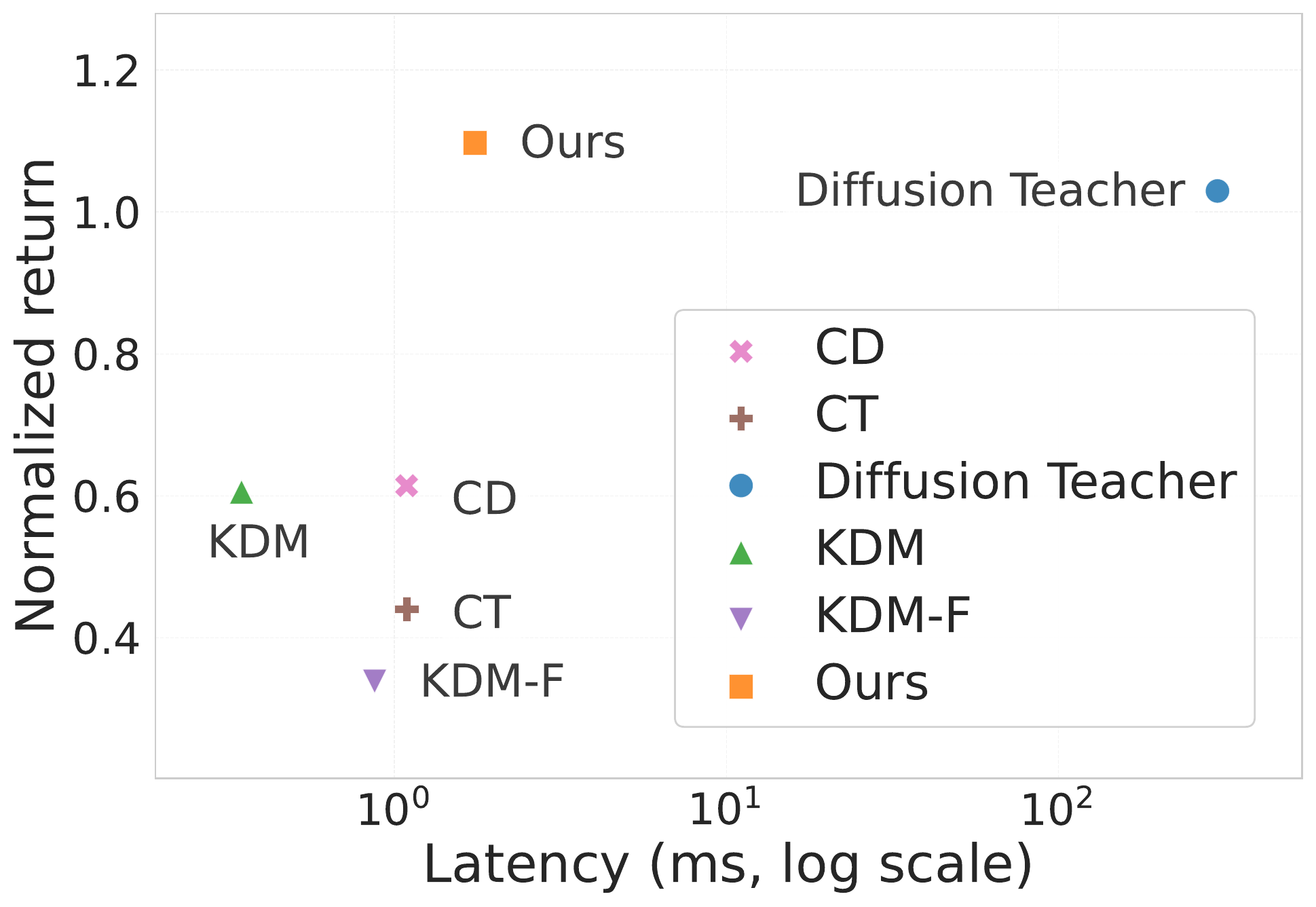
The results show that our method significantly outperforms existing one-step distillation approaches on the reported locomotion tasks, and reduces the inference latency to the millisecond regime compared with the teacher policy. Hardware experiments further demonstrate that our method enables smooth and fast closed-loop execution while maintaining task success and comparable accuracy.
We consider trajectory generation for high-frequency closed-loop robot control. Let \(\mathbf{s}_k \in \mathcal{S} \subseteq \mathbb{R}^{m}\) and \(\mathbf{a}_k \in \mathcal{A} \subseteq \mathbb{R}^{n}\) denote the robot state and action at discrete time \(k\). Over a prediction horizon \(H\), a future state–action trajectory is \[ \boldsymbol{\tau} = (\mathbf{s}_1,\mathbf{a}_1,\dots,\mathbf{s}_H,\mathbf{a}_H). \] At each control step, the planner models a conditional trajectory distribution \(\pi(\boldsymbol{\tau}\mid \mathbf{c})\), where \(\mathbf{c}\) summarizes the information available for planning (e.g., the current observation, short history, and task specification).
Let \(T_{\mathrm{inf}}\) denote the time required to produce usable trajectory samples at inference, and let \(T_{\mathrm{ctrl}}\) denote the control period. For closed-loop deployment, actions must be available within the control period, i.e., \(T_{\mathrm{inf}} \le T_{\mathrm{ctrl}}\). Our goal is a one-step student that cuts \(T_{\mathrm{inf}}\) versus a multistep diffusion teacher while tracking the teacher’s conditional trajectory distribution. MuJoCo results below report return, latency, \(\sigma_{\mathrm{ep}}\), and worst-case return.
halfcheetah-medium-expert-v2 and walker2d-medium-expert-v2 (D4RL MuJoCo; 17-dim observations, 6-dim actions). Teacher training and inference follow the public CleanDiffuser recipe: trajectory diffusion plus a return classifier for guided sampling and candidate ranking, with 20 denoising steps at rollout time.
Mean ± std over 5 seeds. \(\sigma_{\mathrm{ep}}\) = within-run episode variability; worst-case return = minimum seed-level episode mean. Steps = diffusion (teacher) or decision (student) steps at inference.
| Env | Method | Return ↑ | Steps | Latency (ms) ↓ | \(\sigma_{\mathrm{ep}}\) ↓ | Worst-case Return ↑ |
|---|---|---|---|---|---|---|
| Walker2d | Diffusion Teacher | 1.0295 ± 0.0051 | 20 | 301.22 ± 2.41 | 0.0193 | 0.9759 |
| CD | 0.6144 ± 0.0176 | 1 | 1.09 ± 2.33 | 0.0577 | 0.4808 | |
| CT | 0.4404 ± 0.0096 | 1 | 1.09 ± 2.37 | 0.0659 | 0.2591 | |
| KDM | 0.6057 ± 0.0156 | 1 | 0.35 ± 0.04 | 0.0333 | 0.5925 | |
| KDM-F | 0.3386 ± 0.0070 | 1 | 0.87 ± 0.03 | 0.0380 | 0.3267 | |
| Ours | 1.0973 ± 0.0002 | 1 | 1.75 ± 0.36 | 0.0004 | 1.0963 | |
| Ours (classifier selector) | 1.0285 ± 0.0022 | 1 | 4.57 ± 0.87 | 0.0242 | 0.9677 | |
| HalfCheetah | Diffusion Teacher | 0.8518 ± 0.0032 | 20 | 116.51 ± 2.39 | 0.0114 | 0.8229 |
| CD | 0.4027 ± 0.0109 | 1 | 1.08 ± 2.32 | 0.0277 | 0.3217 | |
| CT | 0.4089 ± 0.0047 | 1 | 1.08 ± 2.31 | 0.0198 | 0.3663 | |
| KDM | 0.6618 ± 0.0045 | 1 | 0.34 ± 0.03 | 0.0349 | 0.6571 | |
| KDM-F | 0.4852 ± 0.0098 | 1 | 0.86 ± 0.03 | 0.0216 | 0.4659 | |
| Ours | 0.8885 ± 0.0042 | 1 | 0.82 ± 0.47 | 0.0134 | 0.8488 | |
| Ours (classifier selector) | 0.8599 ± 0.0010 | 1 | 1.83 ± 0.80 | 0.0081 | 0.8417 |
CD / CT: consistency-style one-step baselines. KDM / KDM-F: static Koopman distillation (factorized variant). Ours: proposed dynamic student.

Teacher, Ours, KDM, KDM-F.
Playback speeds are scaled by measured mean decision latency so the teacher’s slower inference is visible next to the student.
Fifty independent real-world trials per method (diffusion teacher vs Ours), with videos and deployment metrics.
Hardware evaluation uses a Kinova Gen3 manipulator in a receding-horizon point-to-point obstacle-avoidance task. At each control step, the policy predicts over a horizon \(H=32\), samples \(N_{\mathrm{cand}}=64\) candidate trajectories, ranks them with a geometry-based score, applies the first action, and replans. The diffusion teacher and our one-step student share the same control interface, scene, and goal specification so latency and task performance are compared under matched conditions.
| Method | Task completion ↑ | Task success ↑ | Completion time (s) ↓ | Executed steps | Inference mean (ms) ↓ | Inference p95 (ms) ↓ | Final goal error ↓ | Min obstacle clearance (m) ↑ | Measured control Hz ↑ | Overrun ratio ↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| Diffusion Teacher | 1.0000 ± 0.0000 | 100% (50/50) | 314.95 ± 3.54 | 25195.62 ± 283.24 | 151.00 ± 3.73 | 158.27 ± 3.78 | 0.003093 ± 0.001421 | 0.046289 ± 0.012908 | 80.005 ± 0.025 | 0.5013 ± 0.0251 |
| Ours | 1.0000 ± 0.0000 | 100% (50/50) | 85.43 ± 2.53 | 6834.24 ± 202.67 | 4.08 ± 0.20 | 4.73 ± 0.23 | 0.003458 ± 0.001745 | 0.048953 ± 0.012117 | 79.999 ± 0.019 | 0.5020 ± 0.0245 |
Mean ± std, 50 trials. Success = count/rate.
Kinova Gen3 hardware evaluation at 2× speed; paired clips support synchronized play and reset.
Second viewpoint for the same receding-horizon point-to-point obstacle-avoidance runs.

Aggregates from the Kinova Gen3 hardware evaluation (same task and protocol as above).




Across the 50 trials summarized above, both methods complete the point-to-point obstacle-avoidance task successfully; Ours matches similar terminal accuracy and clearance while reducing mean per-step inference to the few-millisecond range versus the teacher (see table and plots).